Depuis son lancement public 10 il y a des années, Twitter a été utilisé comme une plate-forme de réseau social entre amis, un service de messagerie instantanée pour les utilisateurs de smartphones et un outil de promotion pour les entreprises et les politiciens.
Mais c'est aussi une source inestimable de données pour les chercheurs et les scientifiques - comme moi - qui veulent étudier comment les humains se sentent et fonctionnent dans des systèmes sociaux complexes.
En analysant les tweets, nous avons pu observer et collecter des données sur les interactions sociales de millions de personnes «dans la nature», en dehors des expériences de laboratoire contrôlées.
Cela nous a permis de développer des outils de suivi de émotions collectives de grandes populations, trouvez le endroits les plus heureux aux États-Unis et bien plus encore.
Alors, comment exactement Twitter est-il devenu une ressource si unique pour les spécialistes des sciences sociales computationnelles? Et qu'est-ce qui nous a permis de découvrir?

Le plus grand cadeau de Twitter aux chercheurs
Juillet 15, 2006, Twittr (comme on le savait alors) publiquement lancé comme un «service mobile qui aide les groupes d'amis à échanger des idées au hasard avec SMS». La possibilité d'envoyer gratuitement des textes de groupe de caractères 140 a poussé de nombreux adopteurs précoces (y compris moi-même) à utiliser la plateforme.
Avec le temps, le nombre d'utilisateurs a explosé: de 20 millions dans 2009 à 200 millions dans 2012 et 310 millions aujourd'hui. Plutôt que de communiquer directement avec des amis, les utilisateurs diraient simplement à leurs adeptes comment ils se sont sentis, réagissent positivement ou négativement aux nouvelles ou font des blagues.
Pour les chercheurs, le plus grand cadeau de Twitter a été la fourniture de grandes quantités de données ouvertes. Twitter a été l'un des premiers grands réseaux sociaux à fournir des échantillons de données grâce à des interfaces de programmation d'applications (API) permettant aux chercheurs d'interroger Twitter sur des types de tweets spécifiques (par exemple, des tweets contenant certains mots). .
Cela a conduit à une explosion de projets de recherche exploitant ces données. Aujourd'hui, une recherche Google Scholar pour "Twitter" produit six millions de visites, contre cinq millions pour "Facebook". La différence est particulièrement frappante étant donné que Facebook a à peu près cinq fois plus d'utilisateurs que Twitter (et a deux ans de plus)
La généreuse politique de données de Twitter a indubitablement mené à une excellente publicité gratuite pour l'entreprise, alors que des études scientifiques intéressantes ont été reprises par les médias grand public.
Étudier le bonheur et la santé
Avec des données de recensement traditionnelles qui sont lentes et coûteuses à collecter, les flux de données ouverts comme Twitter ont le potentiel de fournir une fenêtre en temps réel pour voir les changements dans les grandes populations.
L'Université du Vermont Laboratoire d'histoire informatique a été fondée à 2006 et étudie les problèmes à travers les mathématiques appliquées, la sociologie et la physique. Depuis 2008, le Story Lab a collecté des milliards de tweets via le flux "Gardenhose" de Twitter, une API qui diffuse un échantillon aléatoire de 10 pour cent de tous les tweets publics en temps réel.
J'ai passé trois ans au Computational Story Lab et j'ai eu la chance de participer à de nombreuses études intéressantes utilisant ces données. Par exemple, nous avons développé un hédonomètre cela mesure le bonheur de la Twittersphère en temps réel. En mettant l'accent sur les tweets géolocalisés envoyés à partir de smartphones, nous avons pu Localisation les endroits les plus heureux aux États-Unis. Peut-être sans surprise, nous avons trouvé Hawaii est l'état le plus heureux et viticole Napa la ville la plus heureuse pour 2013.
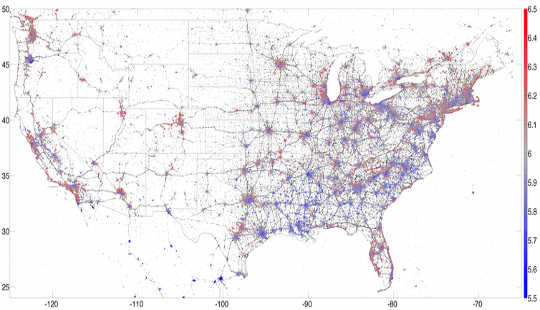 Une carte de 13 millions de tweets US géolocalisés de 2013, colorés par le bonheur, avec le rouge indiquant le bonheur et le bleu indiquant la tristesse. PLoS ONE, Auteur fourni.Ces études avaient des applications plus profondes: Corréler l'utilisation des mots Twitter avec la démographie nous a aidés à comprendre les modèles socio-économiques sous-jacents dans les villes. Par exemple, nous pourrions lier l'utilisation des mots avec des facteurs de santé comme l'obésité, alors nous avons construit un lexicocalorimètre mesurer le "contenu calorique" des messages des médias sociaux. Les tweets d'une région particulière qui mentionnaient les aliments riches en calories augmentaient le «contenu calorique» de cette région, tandis que les tweets qui mentionnaient les activités d'exercice diminuaient notre métrique. Nous avons constaté que cette mesure simple corrèle avec d'autres paramètres de santé et de bien-être. En d'autres termes, les tweets ont pu nous donner un instantané, à un moment précis, de la santé globale d'une ville ou d'une région.
Une carte de 13 millions de tweets US géolocalisés de 2013, colorés par le bonheur, avec le rouge indiquant le bonheur et le bleu indiquant la tristesse. PLoS ONE, Auteur fourni.Ces études avaient des applications plus profondes: Corréler l'utilisation des mots Twitter avec la démographie nous a aidés à comprendre les modèles socio-économiques sous-jacents dans les villes. Par exemple, nous pourrions lier l'utilisation des mots avec des facteurs de santé comme l'obésité, alors nous avons construit un lexicocalorimètre mesurer le "contenu calorique" des messages des médias sociaux. Les tweets d'une région particulière qui mentionnaient les aliments riches en calories augmentaient le «contenu calorique» de cette région, tandis que les tweets qui mentionnaient les activités d'exercice diminuaient notre métrique. Nous avons constaté que cette mesure simple corrèle avec d'autres paramètres de santé et de bien-être. En d'autres termes, les tweets ont pu nous donner un instantané, à un moment précis, de la santé globale d'une ville ou d'une région.
En utilisant la richesse des données Twitter, nous avons également pu voir les mouvements quotidiens des gens dans des détails sans précédent. Comprendre les modèles de mobilité humaine, à son tour, a la capacité de transformer la modélisation de la maladie, ouvrant le nouveau champ de épidémiologie numérique.
Pour d'autres études, nous avons examiné si les voyageurs exprimaient un plus grand bonheur sur Twitter que ceux qui restent à la maison (réponse: ils le font) et si les individus heureux ont tendance à rester ensemble dans un réseau social (encore une fois, ils le font). Effectivement, la positivité semble être cuit dans le langage lui-même, dans le sens où nous avons plus de mots positifs que de mots négatifs. Ce n'était pas le cas seulement sur Twitter, mais dans une variété de médias différents (par exemple, livres, films et journaux) et de langues.
Ces études - et des milliers d'autres similaires du monde entier - n'ont été possibles que grâce à Twitter.
Les prochaines années 10
Alors, que pouvons-nous attendre de Twitter au cours des prochaines années 10?
Certains des travaux les plus excitants impliquent actuellement la connexion des données des médias sociaux avec des modèles mathématiques pour prédire les phénomènes au niveau de la population tels que les épidémies. Les chercheurs ont déjà réussi à enrichir les modèles de maladies avec des données Twitter pour prévoir la grippe, notamment FluOutlook plate-forme développée par la Northeastern University et l'Institute for Scientific Interchange.
Cependant, un certain nombre de défis demeurent. Les données des médias sociaux souffrent d'un très faible «rapport signal sur bruit». En d'autres termes, les tweets qui sont pertinents pour une étude particulière sont souvent noyés par un «bruit» non pertinent.
Par conséquent, nous devons continuellement être conscients de ce qui a été surnommé "Big Data Hubris"Lors du développement de nouvelles méthodes et ne pas être trop confiant de nos résultats. En relation avec ceci devrait être le but de produire des prédictions interprétables de "boîte de verre" à partir de ces données (par opposition aux prédictions "boîte noire", dans lesquelles l'algorithme est caché ou pas clair).
Les données sur les médias sociaux sont souvent (assez) critiquées pour être petites, échantillon non représentatif de la population en général. L’un des défis majeurs pour les chercheurs consiste à trouver un moyen de comptabiliser ces données asymétriques dans des modèles statistiques. Tandis que plus de gens utilisent les médias sociaux chaque année, nous devons continuer à essayer de comprendre les biais dans ces données. Par exemple, les données tendent toujours à surreprésenter les personnes plus jeunes au détriment des populations plus âgées.
Ce n'est qu'après avoir développé de meilleures méthodes de correction des biais que les chercheurs seront en mesure de faire des prédictions totalement confiantes à partir des tweets.
A propos de l'auteur
Lewis Mitchell, maître de conférences en mathématiques appliquées, Université d'Adélaïde
Cet article a été publié initialement le The Conversation. Lis le article original.
Livres connexes
at Marché InnerSelf et Amazon