

Il y a deux ans, l'ancien président Barack Obama a annoncé Initiative de médecine de précision dans son discours sur l'état de l'Union. L'initiative a aspiré à une «nouvelle ère de la médecine» où les traitements de la maladie pourraient être spécifiquement adaptés au code génétique de chaque patient. ![]()
Cela a résonné sainement dans la médecine du cancer. Les patients peuvent déjà gérer leur cancer avec des thérapies qui ciblent les gènes spécifiques qui sont modifiés dans leur tumeur particulière. Par exemple, les femmes atteintes d'un type de cancer du sein causé par l'amplification du gène HER2 sont souvent traitées avec un traitement appelé herceptine. Parce que ces médicaments ciblés sont spécifiques aux cellules cancéreuses, ils ont tendance à avoir moins d'effets secondaires que les traitements traditionnels contre le cancer avec la chimiothérapie ou la radiothérapie.
Cependant, de tels traitements ne sont pas disponibles pour la plupart des patients atteints de cancer. Dans de nombreux cancers, les altérations génétiques spécifiques responsables d'un cancer demeurent inconnues. Pour créer des traitements contre le cancer individualisés, nous devons en savoir plus sur les altérations génétiques fonctionnelles.
Avec des données sur la génétique du cancer en croissance rapide, les mathématiques et les statistiques peuvent maintenant aider à débloquer les modèles cachés dans ces données pour trouver les gènes qui sont responsables du cancer d'un individu. Avec cette connaissance, les médecins peuvent choisir des traitements appropriés qui bloquent l'action de ces gènes pour personnaliser les thérapies pour chaque patient. Ma recherche vise à améliorer la médecine de précision dans le cancer - en s'appuyant sur les mêmes méthodes qui ont été utilisées pour trouver des modèles dans les classements de films Netflix.
Passer au crible les données
Aujourd'hui, il existe un accès public sans précédent aux données sur la génétique du cancer. Ces données proviennent de patients généreux qui donnent leurs échantillons de tumeurs à des fins de recherche. Les scientifiques appliquent ensuite des technologies de séquençage pour mesurer les mutations et l'activité de chacun des gènes 20,000 dans le génome humain.

Toutes ces données sont le résultat direct de Projet du génome humain dans 2003. Ce projet a déterminé la séquence de tous les gènes qui composent l'ADN humain sain. Depuis l'achèvement de ce projet, le coût du séquençage du génome humain a plus de la moitié chaque année, surpassant la croissance de la puissance de calcul décrite dans La loi de Moore. Cette réduction des coûts permet aux chercheurs de collecter des données génétiques sans précédent sur des patients cancéreux.
La plupart des études scientifiques sur la génétique du cancer effectuées à l'échelle mondiale diffusent leurs données dans une base de données publique centralisée fournie par la National Library of Medicine des National Institutes of Health (NIH) des États-Unis. Le NIH National Cancer Institute et l'Institut national de recherche sur le génome humain ont également publié gratuitement des données génétiques sur des tumeurs 11,000 dans les types de cancer 33 grâce à un projet appelé L'Atlas du génome du cancer.
Chaque fonction biologique - de l'extraction de l'énergie de la nourriture à la cicatrisation d'une plaie - résulte de l'activité dans différentes combinaisons de gènes. Les cancers détournent les gènes qui permettent aux gens de devenir adultes et de protéger le corps contre le système immunitaire. Les chercheurs ont ajouté ces "Les caractéristiques du cancer." Ce dérèglement dit de gène permet à une tumeur de croître de façon incontrôlable et de former des métastases dans des organes éloignés du site tumoral d'origine.
Les chercheurs utilisent activement ces données publiques pour trouver l'ensemble des modifications génétiques qui sont responsables de chaque type de tumeur. Mais ce problème n'est pas aussi simple que l'identification d'un seul gène dérégulé dans chaque tumeur. Des centaines, sinon des milliers, des gènes 20,000 dans le génome humain sont dérégulés dans le cancer. Le groupe de gènes dérégulés varie dans la tumeur de chaque patient, avec de plus petits ensembles de gènes communément réutilisés permettant chaque caractéristique du cancer.
La médecine de précision repose sur la découverte des plus petits groupes de gènes dérégulés qui sont responsables de la fonction biologique dans la tumeur de chaque patient. Mais, les gènes peuvent avoir de multiples fonctions biologiques dans différents contextes. Par conséquent, les chercheurs doivent découvrir un ensemble de «chevauchement» des gènes qui ont des fonctions communes dans un ensemble de patients atteints de cancer.
Relier le statut du gène à la fonction nécessite des mathématiques complexes et une immense puissance de calcul. Cette connaissance est essentielle pour prédire l'issue de thérapies qui bloqueraient la fonction de ces gènes. Alors, comment pouvons-nous découvrir ces caractéristiques qui se chevauchent pour prédire les résultats individuels pour les patients?
Ce que Netflix peut nous apprendre
Heureusement pour nous, ce problème a déjà été résolu en informatique. La réponse est une classe de techniques appelée «factorisation matricielle» - et vous avez probablement déjà interagi avec ces techniques dans votre vie quotidienne.
En 2009, Netflix a tenu un défi personnaliser les évaluations de films pour chaque utilisateur Netflix. Sur Netflix, chaque utilisateur dispose d'un ensemble distinct d'évaluations de différents films. Alors que deux utilisateurs peuvent avoir des goûts similaires dans les films, ils peuvent varier considérablement dans des genres spécifiques. Par conséquent, vous ne pouvez pas compter sur la comparaison des notes d'utilisateurs similaires.
Au lieu de cela, un algorithme de factorisation matricielle trouve des films avec des évaluations similaires parmi un plus petit groupe d'utilisateurs. Le groupe d'utilisateurs variera pour chaque film. L'ordinateur associe chaque utilisateur à un groupe de films dans une mesure différente, en fonction de leurs goûts personnels. Les relations entre utilisateurs sont appelées «modèles». Ces modèles sont tirés des données et peuvent trouver des classements communs non prévus par le genre de film uniquement. Par exemple, les utilisateurs peuvent partager une préférence pour un réalisateur ou un acteur particulier.
 Geneviève Stein-O'Brien, CC BY
Geneviève Stein-O'Brien, CC BY
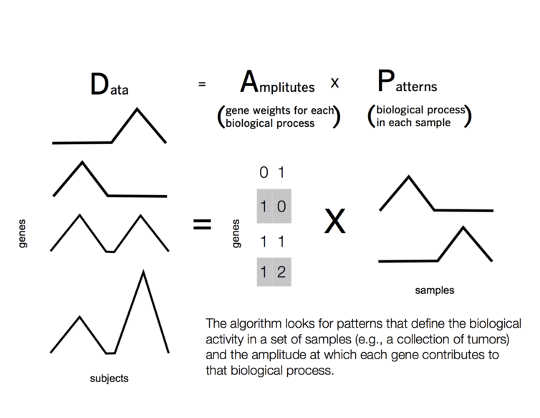
Le même processus peut fonctionner dans le cancer. Dans ce cas, les mesures de dysrégulation des gènes sont analogues aux classifications des films, des genres de films à la fonction biologique et des utilisateurs aux tumeurs des patients. L'ordinateur recherche à travers les tumeurs des patients pour trouver des modèles dans la dérégulation des gènes qui causent la fonction biologique maligne dans chaque tumeur.
Du cinéma aux tumeurs
L'analogie entre les évaluations de films et la génétique du cancer se décompose dans les détails. Sauf s'ils sont mineurs, les utilisateurs de Netflix ne sont pas limités dans les films qu'ils regardent. Mais, au contraire, nos corps préfèrent minimiser le nombre de gènes utilisés pour une seule fonction. Il existe également des redondances substantielles entre les gènes. Pour protéger une cellule, un gène peut facilement se substituer à un autre pour servir une fonction commune. Les fonctions géniques dans le cancer sont encore plus complexes. Les tumeurs sont également très complexes et évoluent rapidement, en fonction des interactions aléatoires entre les cellules cancéreuses et l'organe sain adjacent.
Pour tenir compte de ces complexités, nous avons développé une approche de factorisation matricielle appelée Activité génique coordonnée dans les ensembles de modèles - ou CoGAPS pour court. Notre algorithme tient compte du minimalisme de la biologie en incorporant le moins de gènes possible dans les motifs de chaque tumeur.
Différents gènes peuvent également se substituer, chacun servant une fonction similaire dans un contexte différent. Pour tenir compte de cela, CoGAPS estime simultanément une statistique pour les soi-disant «modèles» de la fonction du gène. Cela nous permet de calculer la probabilité que chaque gène soit utilisé dans chaque fonction biologique d'une tumeur.
Par exemple, de nombreux patients prennent un traitement ciblé appelé cetuximab pour prolonger la survie dans les cancers colorectaux, pancréatiques, pulmonaires et buccaux. Notre travail récent a révélé que ces modèles peuvent distinguer la fonction des gènes dans les cellules cancéreuses qui répondent à l'agent thérapeutique ciblé cetuximab de ceux qui ne répondent pas.
L'avenir
Malheureusement, les traitements anticancéreux qui ciblent les gènes ne peuvent généralement pas guérir la maladie d'un patient. Ils ne peuvent que retarder la progression de quelques années. La plupart des patients rechutent alors avec des tumeurs qui ne répondent plus au traitement.
Notre propre travail récent ont constaté que les modèles qui distinguent la fonction des gènes dans les cellules qui réagissent au cetuximab comprennent les gènes mêmes qui donnent lieu à une résistance. Les immunothérapies émergentes sont prometteuses et semblent guérir certains cancers. Pourtant, trop souvent, les patients avec ces traitements rechutent aussi. Les nouvelles données qui suivent la génétique du cancer après le traitement sont essentielles pour déterminer pourquoi les patients ne répondent plus.
Parallèlement à ces données, la biologie du cancer nécessite également une nouvelle génération de scientifiques qui peuvent établir des ponts entre les mathématiques et les statistiques pour déterminer les changements génétiques qui se produisent au fil du temps dans la pharmacorésistance. Dans d'autres domaines des mathématiques, les programmes informatiques sont en mesure de prévoir les résultats à long terme. Ces modèles sont couramment utilisés dans les prévisions météorologiques et les stratégies d'investissement.
Dans ces domaines et ma propre recherche précédente, nous avons constaté que les mises à jour des modèles à partir de grands ensembles de données - telles que les données satellitaires dans le cas des conditions météorologiques - améliorent les prévisions à long terme. Nous avons tous vu l'effet de ces mises à jour, les prévisions météorologiques s'améliorant au fur et à mesure que nous nous approchons de la tempête.
Tout comme les outils de l'informatique peuvent être adaptés à la fois aux recommandations cinématographiques et au cancer, la future génération de scientifiques informaticiens adoptera des outils de prédiction dans divers domaines pour la médecine de précision. En fin de compte, avec ces outils de calcul, nous espérons prédire la réponse des tumeurs à la thérapie aussi souvent que nous prédisons la météo, et peut-être plus fiable.
A propos de l'auteur
Elana Fertig, professeur adjoint de biostatistique et bioinformatique en oncologie, Johns Hopkins University
Cet article a été publié initialement le The Conversation. Lis le article original.
Livres connexes
at Marché InnerSelf et Amazon



















